
A análise também apontou que esses compradores eram homens que, ao comprarem fraldas para seus filhos, compravam também cerveja para consumo enquanto cuidavam das crianças e assistiam aos jogos na televisão durante o final de semana.
A empresa teria utilizado esse novo conhecimento (data analytics) para colocar lado a lado as gôndolas de fraldas e cervejas na rede de mercados, incrementando assim a venda conjunta dos dois produtos.
Infelizmente, ninguém pode realmente atestar a veracidade da história.
Ora fala-se que as fraldas eram da marca Pampers, ora fala-se em Johnson & Johnson. Alguns citam a Target como a empresa que fez as análises, outros falam no Walmart (caso alguém tenha alguma informação que possa desanuviar o assunto, dividida conosco).
Talvez tenha sido um experimento mental – que nem o Gato de Schrödinger – que fazia sentido.
Tanto que entrou para o folclore da administração.
E faz sentido mesmo, pois ilustra uma das grandes vantagens do Data Mining
A expressão significa mineração de dados em português.
É o processo de descobrir informações acionáveis em grandes conjuntos de dados.
A atividade de Data Mining usa análise matemática para derivar padrões e tendências que existem nos dados.
Normalmente, esses padrões não podem ser descobertos pela exploração de dados tradicionais porque os relacionamentos são muito complexos ou porque há muitos dados.
Esses padrões e tendências podem ser coletados e definidos como um modelo de mineração de dados.
Os modelos de Data Mining podem ser aplicados a cenários específicos.
Por exemplo:
Esses cenários podem ser explorados para descobrir associações (é o caso das fraldas/cervejas) e sequências, classificar os atributos dos conjuntos de dados, aplicar técnicas estatísticas de regressão, clusterização e sumarização, detectar desvios e realizar previsão de séries temporais.
Essa construção faz parte de um processo maior que inclui desde fazer perguntas sobre os dados e criar um modelo para responder a essas perguntas, até implantar o modelo em um ambiente de trabalho.
Este processo pode ser definido usando as seguintes seis etapas básicas:
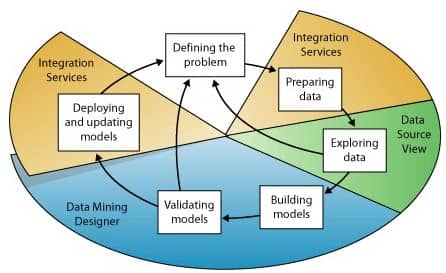
O processo ilustrado no diagrama é cíclico, o que significa que a criação de um modelo de Data Mining é um processo dinâmico e interativo.
Depois de explorar os dados, pode-se descobrir que eles são insuficientes para criar os modelos de mineração apropriados e, portanto, precisa procurar mais dados.
Alternativamente, pode-se construir vários modelos e então perceber que os modelos não respondem adequadamente ao problema que você definiu e que, portanto, você deve redefinir as variáveis.
Pode ser necessário atualizar os modelos depois de implantados, pois mais dados se tornaram disponíveis, levando ao grande desafio do big data analytics, num processo que cresce exponencialmente.
Cada etapa do processo pode precisar ser repetida várias vezes para criar um bom modelo.
Vamos aos 6 passos de como construir um robusto e eficiente modelo:
Esta etapa inclui a análise de requisitos de negócios, definição do escopo do problema, definição das métricas pelas quais o modelo será avaliado e definição de objetivos específicos para o projeto de mineração de dados.
Essas tarefas se traduzem em perguntas como as seguintes:
Para responder a essas perguntas, pode ser necessário conduzir um estudo de disponibilidade de dados, para investigar as necessidades dos usuários de negócios em relação aos dados disponíveis.
Se os dados não atenderem às necessidades dos usuários, pode ser necessário redefinir o projeto.
Você também precisa considerar as maneiras pelas quais os resultados do modelo podem ser incorporados nos indicadores-chave de desempenho (KPI) que são usados para medir o progresso dos negócios.
Os dados podem estar espalhados por uma empresa e armazenados, muitas vezes em um Data Warehouse, em formatos diferentes ou podem conter inconsistências, como entradas incorretas ou ausentes.
Vale um destaque aqui sobre a importância de uma boa governança de dados, para facilitar a manipulação e uso estratégico dos dados.
Por exemplo, os dados podem mostrar que um cliente comprou um produto antes de ele ser oferecido no mercado ou que o cliente compra regularmente em uma loja localizada a 2.000 quilômetros de sua casa.
A limpeza de dados não consiste apenas em remover dados inválidos ou interpolar valores ausentes, mas em encontrar correlações ocultas nos dados, identificar fontes de dados que são mais precisas e determinar quais colunas são mais apropriadas para uso na análise.
Por exemplo, você deve usar a data de envio ou a data do pedido?
As melhores vendas estão influenciando a quantidade, o preço total ou o preço com desconto?
Dados incompletos, dados errados e entradas que parecem separadas, mas na verdade estão fortemente correlacionadas, podem influenciar os resultados do modelo de maneiras que você não espera.
Portanto, antes de começar a construir modelos de mineração, você deve identificar esses problemas e determinar como irá corrigi-los.
Em Data Mining, normalmente, você está trabalhando com um conjunto de dados muito grande e não pode examinar todas as transações quanto à qualidade dos dados; portanto, você pode precisar usar alguma forma de criação de perfil de dados e ferramentas automatizadas de limpeza e filtragem de dados.
É importante observar que os dados usados para mineração de dados não precisam ser armazenados em um cubo OLAP (Online Analytical Processing) ou mesmo em um banco de dados relacional, embora você possa usar ambos como fontes de dados.
Você pode conduzir a mineração de dados usando qualquer fonte de dados que tenha sido definida como uma fonte de dados do Analysis Services.
Isso pode incluir arquivos de texto, pastas de trabalho do Excel ou dados de outros provedores externos.
Você deve compreender os dados para tomar decisões apropriadas ao criar os modelos de mineração.
As técnicas de exploração incluem o cálculo dos valores mínimo e máximo, o cálculo da média e dos desvios padrão e a análise da distribuição dos dados.
Por exemplo, você pode determinar, revisando os valores máximo, mínimo e médio, que os dados não são representativos de seus clientes ou processos de negócios e que, portanto, deve obter dados mais equilibrados ou revisar as suposições que são a base de suas expectativas.
Desvios padrão e outros valores de distribuição podem fornecer informações úteis sobre a estabilidade e precisão dos resultados.
Um grande desvio padrão pode indicar que adicionar mais dados pode ajudá-lo a melhorar o modelo.
Os dados que se desviam fortemente de uma distribuição padrão podem ser distorcidos ou podem representar uma imagem precisa de um problema da vida real, mas tornam difícil ajustar um modelo aos dados.
Explorando os dados à luz de sua própria compreensão do problema de negócios, você pode decidir se o conjunto de dados contém dados incorretos e, em seguida, pode aplicar uma estratégia para corrigir os problemas ou obter uma compreensão mais profunda dos comportamentos típicos de sua empresa.
Você deve definir as colunas de dados que deseja usar criando uma estrutura de mineração.
A estrutura de mineração está vinculada à fonte de dados, mas não contém nenhum dado até que você os processe.
Essas informações podem ser usadas por qualquer modelo de mineração baseado na estrutura.
Antes que a estrutura e o modelo sejam processados, um modelo de mineração de dados também é apenas um contêiner que especifica as colunas usadas para entrada, o atributo que você está prevendo e os parâmetros que informam ao algoritmo como processar os dados.
O processamento de um modelo costuma ser chamado de treinamento.
O treinamento refere-se ao processo de aplicação de um algoritmo matemático específico aos dados da estrutura para extrair padrões.
Os padrões encontrados no processo de treinamento dependem da seleção dos dados de treinamento, do algoritmo escolhido e de como se configurou o algoritmo.
Você também pode usar parâmetros para ajustar cada algoritmo e pode aplicar filtros aos dados de treinamento para usar apenas um subconjunto dos dados, criando resultados diferentes.
Depois de passar os dados pelo modelo, o objeto do modelo de mineração contém resumos e padrões que podem ser consultados ou usados para previsão.
É importante lembrar sempre que os dados mudam, você deve atualizar a estrutura de mineração e o modelo de mineração.
Se você tiver modelos baseados na estrutura, isso significa que eles serão re-treinados nos novos dados.
Antes de implantar um modelo em um ambiente de produção, você desejará testar o desempenho do modelo, contando inclusive com a aplicação de inteligência artificial.
Além disso, ao construir um modelo, você normalmente cria vários modelos com configurações diferentes e testa todos os modelos para ver qual produz os melhores resultados para seu problema e seus dados.
Você usa o conjunto de dados de treinamento para construir o modelo e o conjunto de dados de teste para certificar a precisão do modelo criando consultas de previsão.
Esse particionamento pode ser feito automaticamente durante a construção do modelo de mineração.
Você também pode testar o quão bem os modelos criam previsões usando ferramentas no designer, como o gráfico de elevação e a matriz de classificação.
Para verificar se o modelo é específico para seus dados, ou pode ser usado para fazer inferências na população geral, você pode usar a técnica estatística chamada validação cruzada para criar automaticamente subconjuntos de dados e testar o modelo em cada subconjunto.
Depois que os modelos de mineração existem em um ambiente de produção, você pode executar várias tarefas, dependendo de suas necessidades.
A seguir estão algumas das tarefas que você pode realizar:
A Always On tem bastante experiência nesse processo, em todas as indústrias, como a financeira, varejo, indústria, educacional.
Nossa equipe está preparada para compartilhar as aplicações práticas dos modelos que construiu.
Vamos marcar uma conversa?
Basta enviar email para descomplicando@aodigital.com.br

Confira as técnicas de modelagem de dados para implementar na sua empresa! Você certamente já ouviu dizer que “dados é...

